
Die Auswahl der richtigen cloud-basierten Data-Warehouse-Plattform ist eine strategische Entscheidung, die für Unternehmen von entscheidender Bedeutung ist. Ob Amazon Redshift, Google BigQuery, Microsoft Azure oder Snowflake – der Markt bietet eine Vielzahl von Optionen, und jede Lösung bringt spezifische Stärken und Merkmale mit sich. Während viele der beliebten Data Warehouse Cloud-Plattformen ähnliche Kernfunktionen bieten, unterscheiden sie sich erheblich in Bereichen wie Preisgestaltung, Skalierbarkeit, Architektur, Sicherheitsfunktionen, Geschwindigkeit und weiteren kritischen Faktoren. Dieser detaillierte Vergleich konzentriert sich auf die vier führenden Anbieter im Enterprise-Segment, um Ihnen eine fundierte Entscheidungsgrundlage für Ihr nächstes Cloud Data Warehouse-Projekt zu liefern.
Die Top-Anbieter für Ihr Enterprise Cloud Data Warehouse
Amazon Redshift: Der Pionier im Cloud Data Warehousing
Vor vielen Jahren waren Data Warehouses ausschließlich als On-Premise-Lösungen verfügbar. Im November 2012 revolutionierte Amazon Web Services (AWS) den Markt mit der Einführung von Redshift, einem vollständig verwalteten Data-Warehouse-Service in der Cloud, der Skalierung bis in den Petabyte-Bereich ermöglicht. Obwohl es nicht das erste cloud-basierte Data Warehouse war, erlangte es als erstes eine breite Akzeptanz und signifikante Marktanteile. Redshifts SQL-Dialekt basiert auf PostgreSQL, einer Sprache, die bei Analysten weltweit gut bekannt ist, und seine Architektur ist vielen Nutzern von On-Premise-Data-Warehouses vertraut.
Die Plattform ermöglicht es Ihnen, mit wenigen Gigabytes Daten zu starten und bei Bedarf nahtlos auf Petabytes zu skalieren. Dies versetzt Unternehmen in die Lage, tiefere Einblicke aus ihren Geschäfts- und Kundendaten zu gewinnen und so fundiertere Entscheidungen zu treffen.
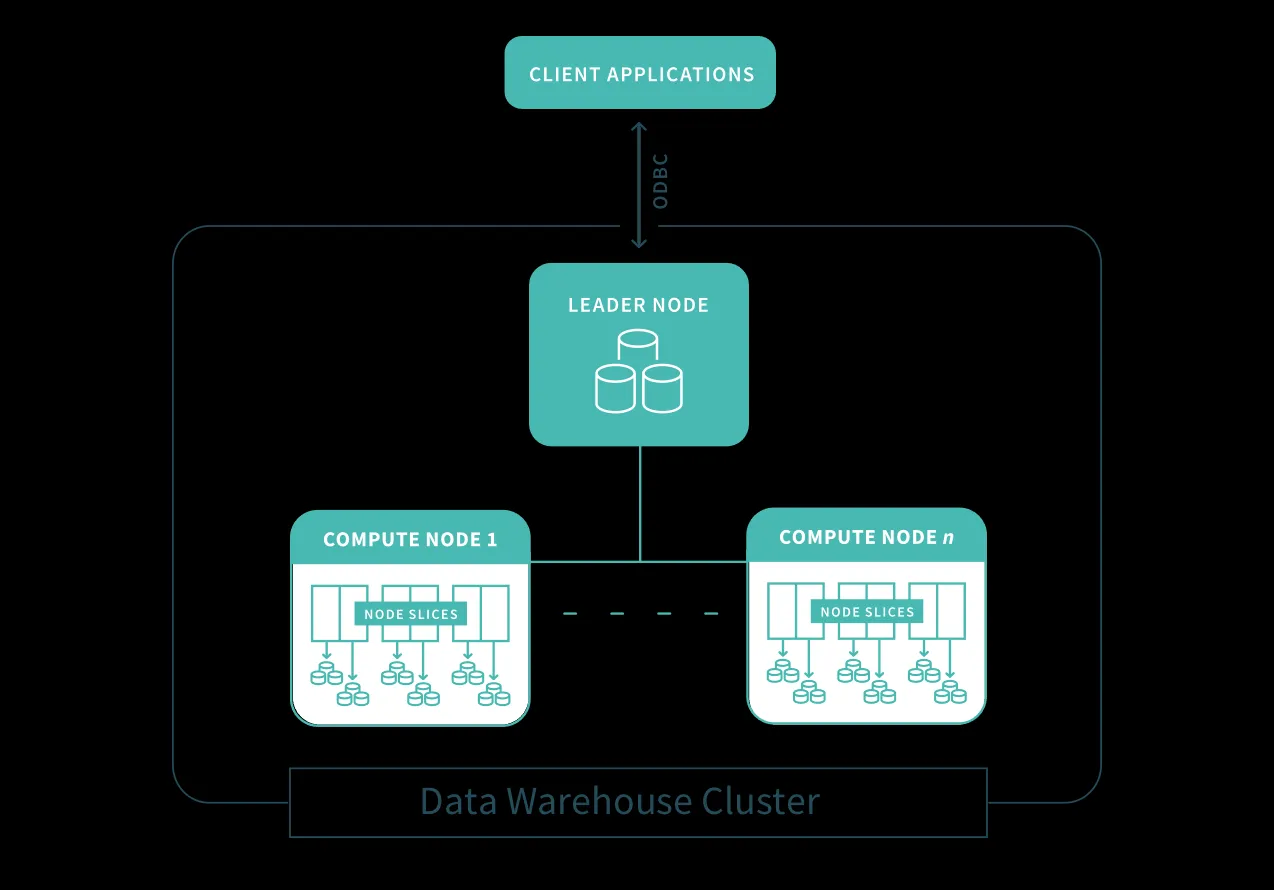 Architekturdiagramm: Client-Anwendungen speisen Daten in einen Amazon Redshift Data Warehouse Cluster ein
Architekturdiagramm: Client-Anwendungen speisen Daten in einen Amazon Redshift Data Warehouse Cluster ein
Der erste Schritt zur Einrichtung eines Redshift Data Warehouses ist das Starten einer Reihe von Knoten, die als Amazon Redshift-Cluster bezeichnet werden. Nach der Bereitstellung Ihres Clusters können Sie Ihre Datensätze hochladen und anschließend Datenanalyseabfragen durchführen. Unabhängig von der Größe Ihres Datensatzes liefert Amazon Redshift eine schnelle Abfrageleistung, wobei vertraute SQL-basierte Tools und Business-Intelligence-Anwendungen genutzt werden können. Diese Eigenschaften machen Redshift zu einer robusten Option für Unternehmen, die einen bewährten Ansatz für ihr Data Warehouse Cloud suchen.
Microsoft Azure Synapse Analytics: SQL-Leistung jenseits des traditionellen Data Warehousing
Azure Synapse Analytics ist ein neuerer Analysedienst, der Enterprise Data Warehousing und Big Data Analytics zusammenführt. Er bietet die Flexibilität, Daten entweder über serverlose On-Demand-Ressourcen oder bereitgestellte Ressourcen abzufragen. Azure Synapse bietet eine einheitliche Oberfläche für das Erfassen, Vorbereiten, Verwalten und Bereitstellen von Daten für Ihre Business Intelligence (BI)- und Machine Learning (ML)-Anforderungen.
Das Herzstück von Azure Synapse ist eine cloud-native, verteilte SQL-Verarbeitungs-Engine, die auf der Grundlage von SQL Server aufgebaut wurde, um die anspruchsvollsten Enterprise Data Warehousing-Workloads zu bewältigen. Ähnlich wie andere Cloud-MPP-Lösungen (Massively Parallel Processing) trennt Azure SQL Data Warehouse (SQL DW) Speicher und Compute, wobei beide separat abgerechnet werden. Azure Synapse speichert relationale Tabellendaten mit spaltenorientiertem Speicher und abstrahiert physische Maschinen, indem es die Rechenleistung in Form von Data Warehouse Units (DWUs) darstellt. Dies ermöglicht es Benutzern, Rechenressourcen einfach und nahtlos nach Bedarf zu skalieren.
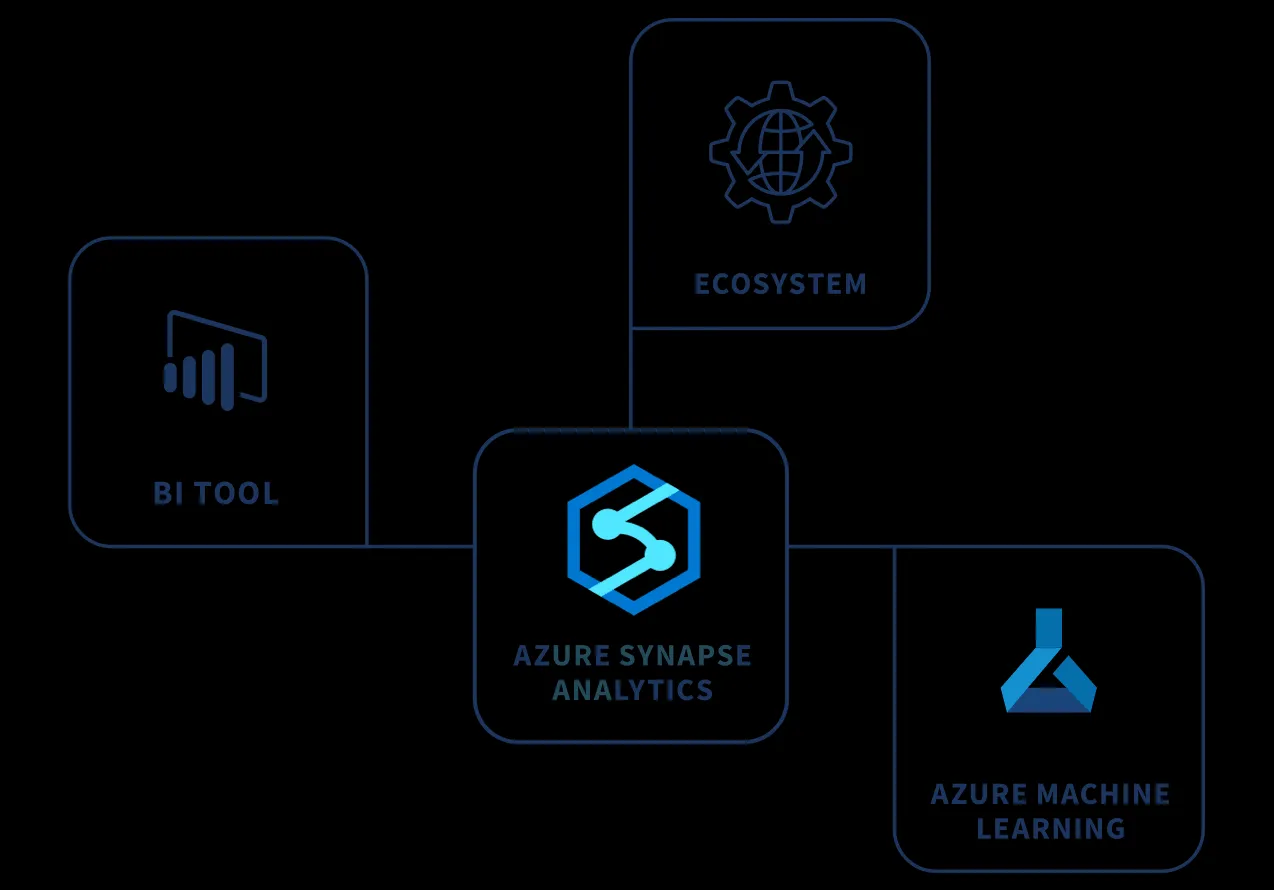 Diagramm von Azure Synapse Analytics, das sich mit BI-Tools, dem Ökosystem und Azure Machine Learning verbindet
Diagramm von Azure Synapse Analytics, das sich mit BI-Tools, dem Ökosystem und Azure Machine Learning verbindet
Synapse Analytics zielt darauf ab, eine Reihe von Analyse-Workloads, wie Data Warehouses oder Data Lakes und ML, in einer einzigen Benutzeroberfläche (UI) zu vereinen. Die Kombination aus einer SQL-Engine, Apache Spark mit Azure Data Lake Storage (ADLS) und Azure Data Factory bietet Benutzern die Möglichkeit, sowohl Data Warehouses/Data Lakes als auch die Datenvorbereitung für ML-Aufgaben zu steuern. Azure Synapse ermöglicht sowohl die vertikale Skalierung des Data Warehouses durch Änderung der Dienststufe oder Platzierung der Datenbank in einem elastischen Pool, als auch die horizontale Skalierung durch Hinzufügen weiterer Data Warehouse Units. Dies macht Azure Synapse zu einer umfassenden Lösung für komplexe Datenstrategien in der Data Warehouse Cloud.
Google BigQuery: Die serverlose Skalierbarkeitslösung
BigQuery ist ein vollständig verwaltetes, serverloses Data Warehouse, das automatisch skaliert, um den Anforderungen an Speicher und Rechenleistung gerecht zu werden. Google nimmt den Nutzern die Verwaltung der Data-Warehouse-Infrastruktur ab, weshalb BigQuery viele der zugrunde liegenden Hardware-, Datenbank-, Knoten- und Konfigurationsdetails verbirgt. Seine Elastizität funktioniert automatisch “out-of-the-box”. Der Einstieg ist denkbar einfach: Man erstellt ein Konto bei der Google Cloud Platform (GCP), lädt eine Tabelle und führt eine Abfrage aus. Google kümmert sich um den Rest.
Mit BigQuery erhalten Sie eine spaltenorientierte und ANSI-SQL-Datenbank, die Terabytes bis Petabytes an Daten mit unglaublicher Geschwindigkeit analysieren kann. BigQuery ermöglicht auch räumliche Analysen mit vertrautem SQL über BigQuery GIS. Darüber hinaus können Sie schnell ML-Modelle auf großen strukturierten oder semi-strukturierten Daten mit einfachem SQL über BigQuery ML erstellen und operationalisieren. Und mit BigQuery BI Engine können Sie interaktives Echtzeit-Dashboarding unterstützen.
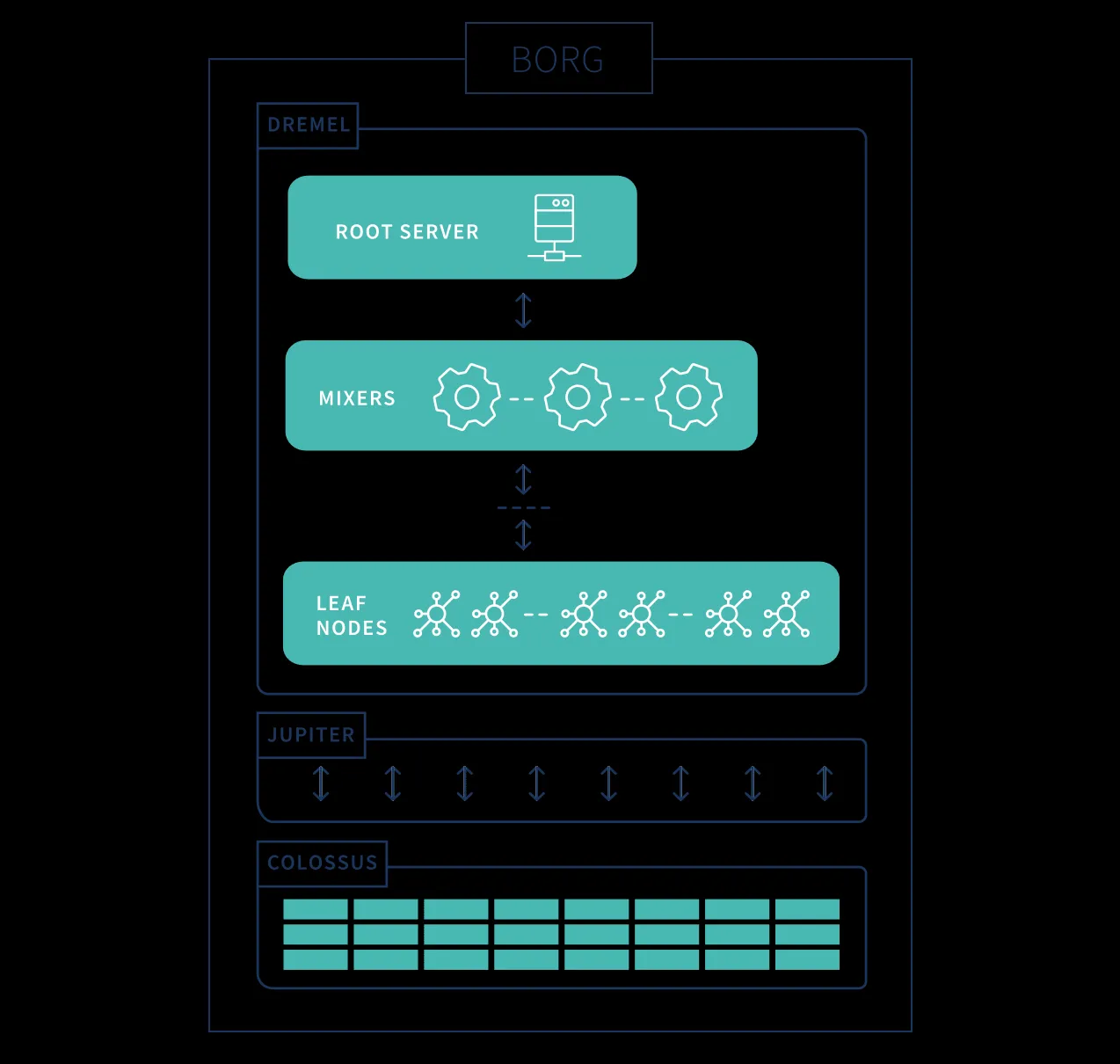 Hierarchische Netzwerkarchitektur von Google BigQuery mit Root-Server, Mixern und Leaf Nodes
Hierarchische Netzwerkarchitektur von Google BigQuery mit Root-Server, Mixern und Leaf Nodes
Die BigQuery-Architektur besteht aus mehreren Komponenten: Borg für die Compute-Ressourcen, Colossus für den verteilten Speicher, Jupiter für das Netzwerk und Dremel als Ausführungs-Engine. Diese Komponenten arbeiten nahtlos zusammen, um die beeindruckende Leistung und Skalierbarkeit zu gewährleisten, die Google BigQuery als Data Warehouse Cloud auszeichnet.
Snowflake Cloud Data Warehouse: Das erste Multi-Cloud-Angebot
Snowflake ist ein vollständig verwaltetes MPP (Massively Parallel Processing) cloud-basiertes Data Warehouse, das auf AWS, GCP und Azure läuft. Im Gegensatz zu den anderen hier vorgestellten Data Warehouses ist Snowflake die einzige Lösung, die nicht auf einer eigenen Cloud-Infrastruktur betrieben wird. Mit einer gemeinsamen und austauschbaren Codebasis bietet Snowflake globale Datenreplikation, was bedeutet, dass Sie Ihre Daten in jede Cloud, in jede Region verschieben können – ohne Ihre Anwendungen neu programmieren oder neue Fähigkeiten erlernen zu müssen.
Als Snowflake-Nutzer können Sie beliebig viele virtuelle Warehouses hochfahren, um die Leistung einzelner Abfragen zu parallelisieren und zu isolieren. Snowflake ermöglicht eine sehr hohe Parallelität, indem es Speicher und Compute trennt, um sicherzustellen, dass viele Warehouses gleichzeitig auf dieselbe Datenquelle zugreifen können.
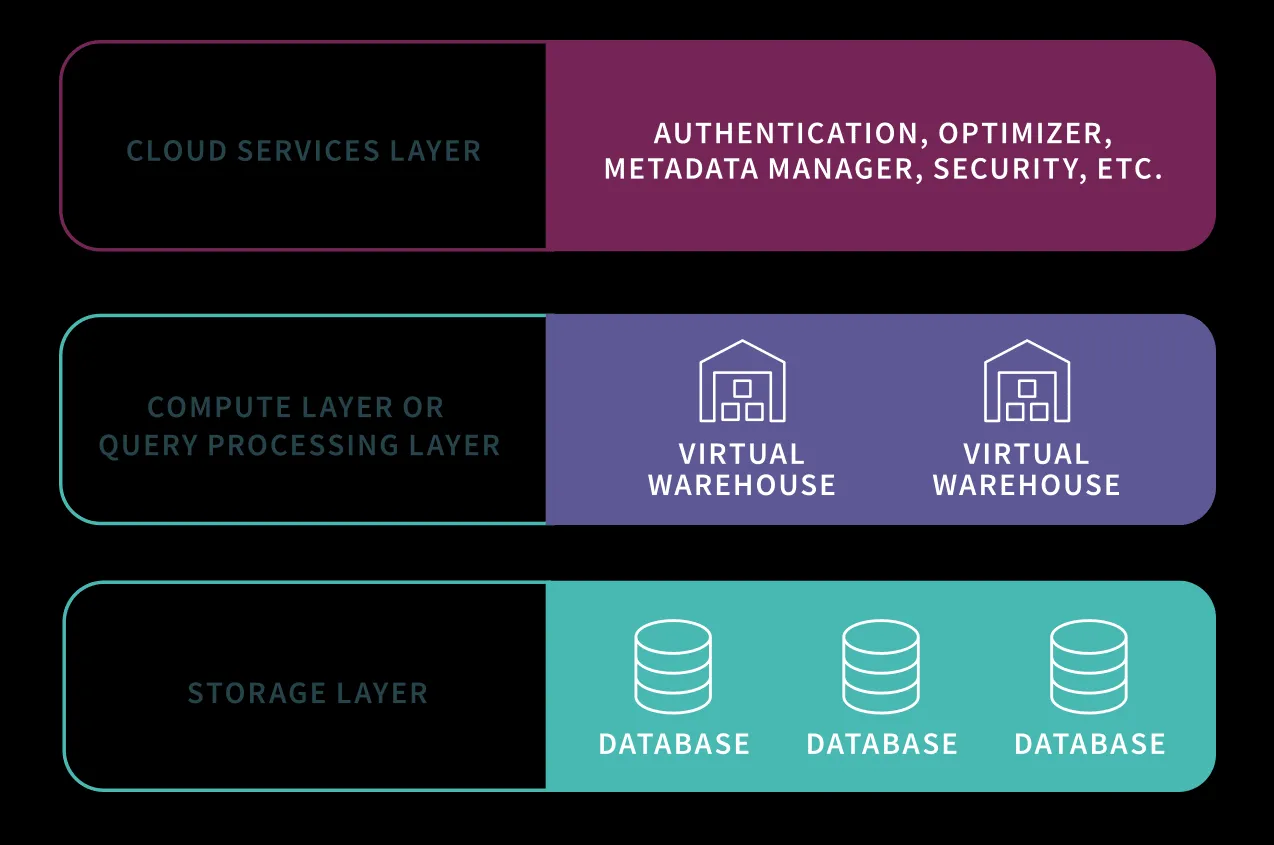 Architekturdiagramm von Snowflake mit Authentifizierung, virtuellen Warehouses und Speicherschichten
Architekturdiagramm von Snowflake mit Authentifizierung, virtuellen Warehouses und Speicherschichten
Sie interagieren mit Snowflakes Data Warehouse über einen Webbrowser, die Kommandozeile, eine Analyseplattform oder über Snowflakes ODBC-, JDBC- oder andere unterstützte Treiber. Die Plattform unterstützt ACID-konforme relationale Verarbeitung und bietet native Unterstützung für Dokumentenspeicherformate wie JSON, Avro, ORC (Optimized Row Columnar), Parquet und XML. Diese Multi-Cloud-Fähigkeit und die Flexibilität in der Datenverarbeitung machen Snowflake zu einer attraktiven Option für Unternehmen, die eine agnostische Data Warehouse Cloud-Lösung suchen.
Zusammenfassend lässt sich sagen, dass die Wahl des passenden Data Warehouse Cloud-Anbieters von Ihren spezifischen Anforderungen an Skalierbarkeit, Integration, Kostenstruktur und der bestehenden Infrastruktur abhängt. Jede der vorgestellten Plattformen – Amazon Redshift, Microsoft Azure Synapse Analytics, Google BigQuery und Snowflake – bietet einzigartige Vorteile und passt zu unterschiedlichen Geschäftsszenarien. Eine sorgfältige Analyse Ihrer Datenstrategie und Betriebsbedürfnisse ist unerlässlich, um die optimale Lösung zu finden, die Ihre Analysetätigkeiten bestmöglich unterstützt und Innovationen vorantreibt.
Entdecken Sie weitere Ressourcen und detaillierte Vergleiche, um Ihre Entscheidung zu erleichtern und das volle Potenzial Ihres Cloud Data Warehouse auszuschöpfen.