
Der chinesische Technologiegigant Tencent hat kürzlich zwei spezialisierte Übersetzungsmodelle als Open Source veröffentlicht, die nach eigenen Angaben etablierte Tools wie Google Translate in internationalen Benchmarks deutlich übertreffen. Diese Entwicklung markiert einen bedeutenden Schritt in der maschinellen Übersetzung und verspricht, die Zugänglichkeit und Qualität von Übersetzungsdiensten weltweit zu verbessern. Besonders hervorzuheben ist ihre Leistungsfähigkeit, gemessen an kritischen Metriken wie den XCOMET-XXL-Scores, die sie an die Spitze der Branche katapultiert.
Bahnbrechende Leistung bei globalen Benchmarks
Beim WMT2025, einem führenden Workshop, bei dem Forschungsteams ihre Übersetzungssysteme vergleichen, belegten Tencents neue Modelle Hunyuan MT 7B und Hunyuan MT Chimera 7B in 30 von 31 getesteten Sprachpaaren den ersten Platz. Das “Workshop on Machine Translation” (WMT) ist eine der renommiertesten Veranstaltungen zur Bewertung von Übersetzungsmodellen. Diese Ergebnisse untermauern die herausragende Qualität und Präzision, die die Hunyuan-Modelle in einem breiten Spektrum von Sprachkombinationen erreichen können. Die beeindruckenden XCOMET-XXL-Scores belegen, dass diese Modelle nicht nur theoretisch, sondern auch praktisch in der Lage sind, komplexe Übersetzungsaufgaben mit hoher Genauigkeit zu bewältigen.
Beide Modelle unterstützen die bidirektionale Übersetzung in 33 Sprachen, darunter weit verbreitete wie Chinesisch, Englisch und Japanisch, aber auch weniger häufig digitalisierte Sprachen wie Tschechisch, Marathi, Estnisch und Isländisch. Ein besonderer Schwerpunkt von Tencent liegt auf der Übersetzung zwischen Mandarin-Chinesisch und Minderheitensprachen in China. Die Modelle ermöglichen die beidseitige Übersetzung zwischen Chinesisch und Kasachisch, Uigurisch, Mongolisch sowie Tibetisch. Diese breite Sprachabdeckung, gepaart mit den beeindruckenden Leistungsdaten, macht die Hunyuan-Modelle zu einem mächtigen Werkzeug für eine Vielzahl von Anwendungsfällen.
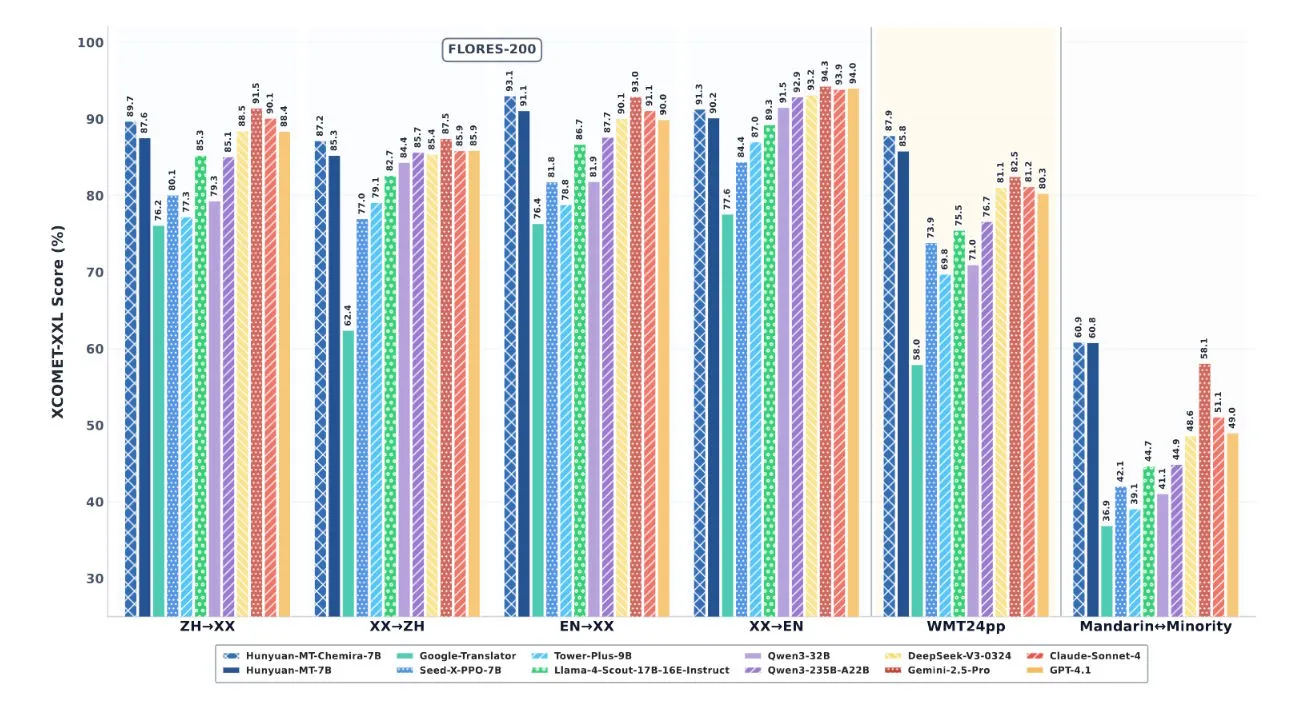 Balkendiagramm zeigt XCOMET-XXL-Scores für verschiedene Übersetzungsmodelle in sechs Kategorien, wobei Tencents Hunyuan-Modelle hohe Werte erreichen
Balkendiagramm zeigt XCOMET-XXL-Scores für verschiedene Übersetzungsmodelle in sechs Kategorien, wobei Tencents Hunyuan-Modelle hohe Werte erreichen
7B-Parameter-Modelle übertreffen größere Konkurrenten
Tencents technischer Bericht zeigt, dass die Hunyuan-Modelle etablierte Systeme in direkten Vergleichen schlagen. Im Vergleich zu Google Translate verbesserten sich die Ergebnisse je nach Sprachrichtung und Bewertungskriterien um 15 bis 65 Prozent. Auch proprietäre KI-Systeme wie GPT-4.1, Claude 4 Sonnet und Gemini 2.5 Pro blieben in den meisten Tests hinter den Erwartungen zurück. Die Fähigkeit dieser Modelle, solche Ergebnisse zu erzielen, während sie gleichzeitig eine relativ geringe Parameterzahl aufweisen, ist bemerkenswert und deutet auf eine hohe Effizienz hin.
Mit 7 Milliarden Parametern sind diese Modelle deutlich kleiner als viele Grundmodelle ihrer Klasse. Dies bedeutet, dass sie weniger Rechenleistung benötigen und auf schwächerer Hardware laufen können, was ihre Zugänglichkeit erheblich verbessert. Benchmarks zeigen, dass sie dennoch in der Leistung mit größeren Systemen mithalten oder diese sogar übertreffen. Insbesondere überflügeln sie die Tower Plus-Serie (mit bis zu 72 Milliarden Parametern) um 10 bis 58 Prozent. In direkten Tests mit wichtigen Sprachpaaren zeigten beide Hunyuan-Modelle deutliche Zuwächse. Im Vergleich zu Gemini 2.5 Pro erzielten sie etwa 4,7 Prozent höhere XCOMET-XXL-Scores. Im Vergleich zu spezialisierten Übersetzungsmodellen lagen die Verbesserungen sogar zwischen 55 und 110 Prozent. Die Modelle sind als Open Source auf Hugging Face verfügbar, und Tencent hat den Quellcode auch auf GitHub veröffentlicht.
Fortschrittliche Trainingspipeline für überragende Ergebnisse
Tencent verwendete einen fünfstufigen Trainingsprozess: Beginnend mit allgemeinem Text, gefolgt von der Verfeinerung mit übersetzungsspezifischen Daten, anschließend überwachtem Lernen mit Beispielübersetzungen, Reinforcement Learning mit Belohnungssignalen und einem abschließenden “weak-to-strong” Reinforcement Learning-Schritt. Diese mehrstufige Herangehensweise ermöglichte es den Modellen, ein tiefes Verständnis für Sprachnuancen und Kontext zu entwickeln, was zu den überragenden Übersetzungsleistungen führt.
Die Trainingsdaten umfassten allein für Minderheitensprachen 1,3 Billionen Tokens, die 112 Sprachen und Dialekte abdeckten. Ein maßgeschneidertes Bewertungssystem überprüfte die Daten auf Wissenswert, Authentizität und Schreibstil. Das Chimera-Modell verwendet einen Fusionsansatz, der mehrere Übersetzungsvorschläge verschiedener Systeme kombiniert, um ein stärkeres Endergebnis zu generieren. Tencent gibt an, dass diese Methode die standardmäßige Testleistung um durchschnittlich 2,3 Prozent verbesserte. Während Tencent die Grenzen der Open-Source-Übersetzung neu definiert, kündigte Google kürzlich neue KI-Funktionen für seinen Übersetzungsdienst an, darunter Live-Übersetzung für Echtzeitgespräche und einen personalisierten Sprachlernmodus, angetrieben durch die fortschrittlichen Denk- und multimodalen Fähigkeiten der Gemini-Modelle.
Abschließend lässt sich festhalten, dass Tencents Hunyuan MT-Modelle einen beeindruckenden Fortschritt in der maschinellen Übersetzung darstellen. Ihre Fähigkeit, mit 7 Milliarden Parametern derart hohe XCOMET-XXL-Scores zu erzielen und dabei etablierte, größere Konkurrenten zu übertreffen, ist ein klares Zeichen für die Effizienz und Innovation in Tencents Forschungs- und Entwicklungsprozess. Die Open-Source-Verfügbarkeit dieser Modelle verspricht zudem, die Innovation in der gesamten KI-Gemeinschaft voranzutreiben und neue Möglichkeiten für Entwickler und Forscher zu eröffnen.